What Are We Pointing At?

Some years ago, I wrote a play about a Viennese doctor in Paris in 1784 named Franz Anton Mesmer. (From him we get the word ‘mesmerize’). His most famous case was a young blind pianist named Maria Theresa Paradis.
His patients grasped iron bars that protruded from a wooden tub filled with water and iron filings. He felt that we humans conducted magnetism — but a variation on magnetism — something called Animal Magnetism. It came to have a sexual connotation (attraction) because Mesmer, when he saw one of his patients go into the ‘crisis’ — trembling and gasping — would take them into the ‘crisis room’ and deal with them privately there. People jumped to their own conclusions, naturally.
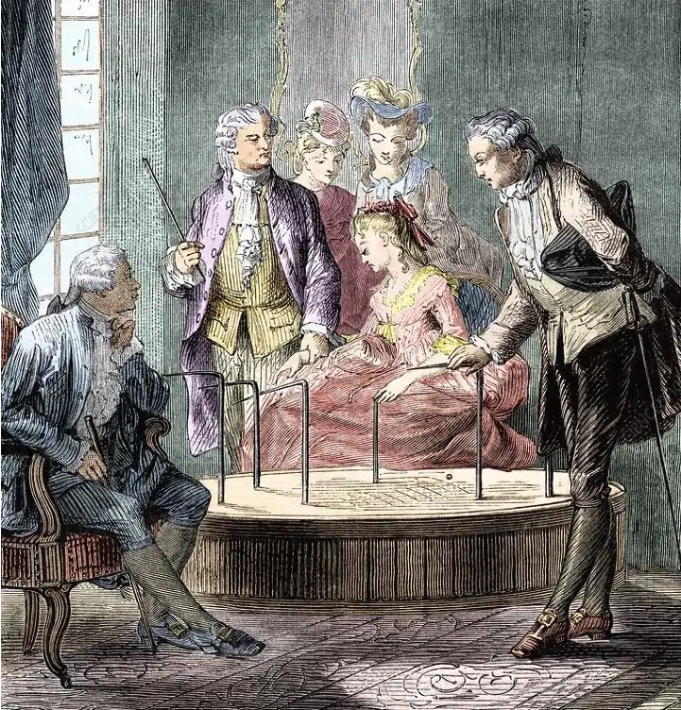
Here is part of a scene from that play, in which Mesmer cures the young woman of blindness and unwraps her eyes for the first time.
(Mesmer picks up a small white sack and pulls out a white ball.)
Mesmer: Sphere.
Maria: Sphere.
Mesmer (pulling out a red ball): Sphere.
Maria: Sphere.
Mesmer (pulling out a yellow ball): Sphere.
Maria: Sphere.
Mesmer (taking out a red cube): Cube.
Maria: Cube.
Mesmer (taking out a yellow cube): Cube.
Maria: Cube.
Mesmer (laying out the yellow cube, the yellow ball, and a yellow cloth): Yellow.
Maria (with a gasp, the idea dawning on her): Yellow!
So what I was getting at was this: what is he pointing at? How does she know which feature he’s pointing at? There is really only one way to know, and that is by repetition. When he has three things together, all of which share one property, that’s how you know which property is being pointed out.
Similarly, if you take a piece of white pine, a branch of maple, a wooden puzzle box, and a little horse cut out of wood, and asked someone: “what am I pointing at?” they would very likely get it right. If they didn’t get it right, you could always add more examples.
The young woman had no reference for something like a color (at least not yet). And so she stands in for a computer, for machine learning. What are we pointing at? What happens in a deep learning neural network is that the network ‘learns’ according to properties that are shared across instances in the data. This is a training signal. It is often a label, in a supervised learning training set. In order for the system to know what is a face and what isn’t, it needs a training set labeled with ‘this is a face and this one isn’t.’
This has become extremely effective for tasks like image classification. We could certainly label a training set as ‘squares’ or ‘cubes’ or ‘spheres’. We could also label them by color. But what if we want to point to subtler aspects of the training set? Put another way, how can we guide the attention of the neural net?
In particular I’m thinking of language.
The whole point of deep learning and neural networks is that you don’t need to ‘feature engineer’ — meaning that, in essence, you let the network figure out what you’re pointing at, just by having a training signal, like a label. But if that is what you want, you’re going to have to approach the labeling with subtlety and precision.
“I’ve had it up to here.” This has the idea in it of excess: like a river overflowing its banks, or a faucet left on in the kitchen that overfills a glass. Or someone who is speeding, or is too young to get married, or is bursting with love. It’s outside the bounds. It even, though to a lesser degree, has something in common with the idea of being exhausted, or spent, though that appears in the negative direction. So it is recognizable across time (from the original example), space, age, volume (the water) and a host of other contexts.
One thing to notice is that the concept need have no words in common from one domain to the next. Word vectors such as word2vec or GloVe work by the distributional hypothesis, which is that linguistic items with similar distributions have similar meanings, or, a word is characterized by the company it keeps. This is surprisingly effective, but it doesn’t get us directly to meaning in the sense that the above examples do. And it does lend itself to error, since words of opposite meaning may have very similar frequencies to surrounding words.
What does this suggest? It suggests that in order to indicate meaning to a machine, we need a way to indicate concepts in a way that has very little to do with the actual words used, in the manner suggested above. That which we recognize is necessarily general, as it contains components, or ‘primitives’ that we recognize across domains and situations (speeding, too young, overflowing, a moment too long, etc.).
And, then, what is the question? The question is: once we suggest these recognized patterns to the machine, will it be able to generalize? How many examples will it require before it can do so?
The answer to the former is, very likely, yes. The complexity of this task wouldn’t seem much more complex than image recognition, with its complexity born of distance from the subject, angles, lighting, partially obstructed, views, varieties of faces, etc.